
 2024-04-30
2024-04-30
 GoogleMeet, テキストファイル, マークダウンファイル, 文字コード, 文書構造, 画像ファイル
GoogleMeet, テキストファイル, マークダウンファイル, 文字コード, 文書構造, 画像ファイル
ICT基礎 第3回
ICT基礎 第3回Google Meet今日のフォルダの準備今日のサンプルファイル集文字の表現文字コードASCII実際に文字に割り当てられた数を確認するUnicode文字化けさせてみよう画像ファイルラスタとベクタ具体例 (ラスタ)具体例 (ベクタ)文書構造概要マークダウンファイルマークダウンファイルの作成マークダウン言語の基本見出し箇条書きリンクマークダウンのプレビューを表示する文書を構造化してみるマークダウンファイルをpdf出力するMarkdown pdfのインストールMarkdown pdfでpdf出力するPDF化の選択肢が出てこない場合 (Restricted Mode, 制限モード)広義のテキストファイル課題
Google Meet
GWなので, Google Meetをオープンしておきます. 私自身は大学で授業しているため, 気づくのが遅れるかもしれませんが, わからない点があればコメントで質問してください.
ICT基礎 5月 2日 (木曜日) · 午後2:30~6:00 タイムゾーン: Asia/Tokyo Google Meet の参加に必要な情報 ビデオ通話のリンク: https://meet.google.com/apg-ekav-xqr
今日のフォルダの準備
Windows:
C:\Users\[ユーザ名]\Documents\ictに移動し,03というフォルダを作成しておくC:\Users\[ユーザ名]\Documents\ict\03というフォルダ構成になる
Mac:
/Users/[ユーザ名]/Documents/ict/に移動し,03というフォルダを作成しておく/Users/[ユーザ名]/Documents/ict/03
文字の表現
文字コード
コンピュータの中では, 実際にbitという0 or 1を用いて様々なものを表現しています.
シンプルな例は文字です. 活版印刷が生まれる以前, 文字は下図のような手書きによるものでした.

上図では, 上の行と下の行とで同じ内容: a b c あ い う 漢 字 を書いています.
誰が書いても, どんなに汚く or キレイに書いても文字は文字で, 等しく a b c あ い う 漢 字 という同じ内容を示します.
すなわち, 汚い, キレイ, かっこいい, 太い, 細い, 大きい, 小さい等の要素は, 文字の本質ではなく, 装飾であることがわかります. そして, 活版印刷の活字が生まれたことで, 文字自体と, その装飾との区別がより明確になっていきます.
コンピュータで文字を表現する場合も同じです. 文字そのものを表現する共通の方法を用意することが基礎としてあり, 文字の装飾は機器やアプリごとに異なっても良いのです.
コンピュータが扱えるのは (原始的には) 数のみであるため, 文字に数を割り当てる (例: K↔75) ことで文字を表現します. この割り当て方のルールを文字コード (character code) と呼びます.
世界中にただ1つの文字コードしか存在しない、という状況なら特に困らないのですが, 現実はそうではありません. 英語のようにアルファベット26文字で済む場合もあれば, 日本語のように, ひらがな, カタカナ, 漢字など大量の文字を必要とする言語もあります.
各々が各々のルールで文字と数とを割り当ててきた歴史があるため, 現状では様々な文字コードが存在します.
例: ASCII, EBCDIC, JIS, Shift_JIS, EUC, Unicode 等
ASCII
これらの文字コードの中で, 最も基本的な文字コードと呼ばれるものが ASCII (アスキー) です.
アルファベット, 数字, いくつかの記号, そして制御文字 (改行など) を, 7bit (2進数なら7桁の0000000 ~ 1111111, 10進数なら0 ~ 127, 16進数なら0 ~ 7F) で1文字を表します. 他の文字コードでも, この128文字はASCIIと共通している場合がほとんどです.
具体的には下表です. 青文字は制御文字, それ以外が印刷可能文字です.
| 2進数 | 10進 | 16進 | 文字 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0000000 | 0 | 00 | NUL (ヌル) | 0111111 | 63 | 3F | ? | 1100010 | 98 | 62 | b | ||
| : | : | : | : | 1000000 | 64 | 40 | @ | 1100011 | 99 | 63 | c | ||
| 0001010 | 10 | 0A | LF (改行) | 1000001 | 65 | 41 | A | 1100100 | 100 | 64 | d | ||
| : | : | : | : | 1000010 | 66 | 42 | B | 1100101 | 101 | 65 | e | ||
| 0100000 | 32 | 20 | Space | 1000011 | 67 | 43 | C | 1100110 | 102 | 66 | f | ||
| 0100001 | 33 | 21 | ! | 1000100 | 68 | 44 | D | 1100111 | 103 | 67 | g | ||
| 0100010 | 34 | 22 | " | 1000101 | 69 | 45 | E | 1101000 | 104 | 68 | h | ||
| 0100011 | 35 | 23 | # | 1000110 | 70 | 46 | F | 1101001 | 105 | 69 | i | ||
| 0100100 | 36 | 24 | $ | 1000111 | 71 | 47 | G | 1101010 | 106 | 6A | j | ||
| 0100101 | 37 | 25 | % | 1001000 | 72 | 48 | H | 1101011 | 107 | 6B | k | ||
| 0100110 | 38 | 26 | & | 1001001 | 73 | 49 | I | 1101100 | 108 | 6C | l | ||
| 0100111 | 39 | 27 | ' | 1001010 | 74 | 4A | J | 1101101 | 109 | 6D | m | ||
| 0101000 | 40 | 28 | ( | 1001011 | 75 | 4B | K | 1101110 | 110 | 6E | n | ||
| 0101001 | 41 | 29 | ) | 1001100 | 76 | 4C | L | 1101111 | 111 | 6F | o | ||
| 0101010 | 42 | 2A | * | 1001101 | 77 | 4D | M | 1110000 | 112 | 70 | p | ||
| 0101011 | 43 | 2B | + | 1001110 | 78 | 4E | N | 1110001 | 113 | 71 | q | ||
| 0101100 | 44 | 2C | , | 1001111 | 79 | 4F | O | 1110010 | 114 | 72 | r | ||
| 0101101 | 45 | 2D | - | 1010000 | 80 | 50 | P | 1110011 | 115 | 73 | s | ||
| 0101110 | 46 | 2E | . | 1010001 | 81 | 51 | Q | 1110100 | 116 | 74 | t | ||
| 0101111 | 47 | 2F | / | 1010010 | 82 | 52 | R | 1110101 | 117 | 75 | u | ||
| 0110000 | 48 | 30 | 0 | 1010011 | 83 | 53 | S | 1110110 | 118 | 76 | v | ||
| 0110001 | 49 | 31 | 1 | 1010100 | 84 | 54 | T | 1110111 | 119 | 77 | w | ||
| 0110010 | 50 | 32 | 2 | 1010101 | 85 | 55 | U | 1111000 | 120 | 78 | x | ||
| 0110011 | 51 | 33 | 3 | 1010110 | 86 | 56 | V | 1111001 | 121 | 79 | y | ||
| 0110100 | 52 | 34 | 4 | 1010111 | 87 | 57 | W | 1111010 | 122 | 7A | z | ||
| 0110101 | 53 | 35 | 5 | 1011000 | 88 | 58 | X | 1111011 | 123 | 7B | { | ||
| 0110110 | 54 | 36 | 6 | 1011001 | 89 | 59 | Y | 1111100 | 124 | 7C | | | ||
| 0110111 | 55 | 37 | 7 | 1011010 | 90 | 5A | Z | 1111101 | 125 | 7D | } | ||
| 0111000 | 56 | 38 | 8 | 1011011 | 91 | 5B | [ | 1111110 | 126 | 7E | ~ | ||
| 0111001 | 57 | 39 | 9 | 1011100 | 92 | 5C | \ | 1111111 | 127 | 7F | DEL (削除) | ||
| 0111010 | 58 | 3A | : | 1011101 | 93 | 5D | ] | ||||||
| 0111011 | 59 | 3B | ; | 1011110 | 94 | 5E | ^ | ||||||
| 0111100 | 60 | 3C | < | 1011111 | 95 | 5F | _ | ||||||
| 0111101 | 61 | 3D | = | 1100000 | 96 | 60 | ` | ||||||
| 0111110 | 62 | 3E | > | 1100001 | 97 | 61 | a |
実際に文字に割り当てられた数を確認する
VS CodeにHex Editorという拡張機能を入れると, テキストファイル内の「各文字に割り当てられた数 (16進数表現) 」を確認できます.

Hex Editorと導入方法と使い方の動画は下記の通りです.
導入方法
VS Codeを開いた状態にする
左側の3つの四角と1つの四角が書かれたマーク
 をクリックする
をクリックする左横に出てきた列の上部の検索ボックスに
hex editorと入力するHex Editorというツールの
installボタンをクリックこれでHex Editorという拡張ツールがVS Codeにインストールされた
使い始め方
VS Codeでテキストファイル (
hex-test.txt) を開いた状態にするWindows: Ctrl キーとShiftキーを押したまま pキーを押す Mac: Command キーとShiftキーを押したまま pキーを押す
Hex Editor: Open Active File in Hex Editorをクリックテキストデータ内の文字に割り当てられた数を確認できる新しいタブが開く
テスト方法
適当に文字を入力し, 上書き保存: Windows: Ctrl + s Mac: Command + s
テキストに割り当てられた数が表示される
| 動画 |
Unicode
上記で紹介したASCIIには日本語や他の言語の文字が含まれていません.
そこで, 各国がASCIIを拡張して独自の文字コードを作っていきました. 自国内で閉じて使用している分にはまだ良かったのですが, 国際化が進むにつれ, 異なる言語間のメールでやり取りする場面が増えていきました.
すると, ある数に割り当てられた文字というのが, 文字コードごとに異なるため, 異なる言語間のメールにおいて, 意図しない文字が表示されてしまう問題が発生しました. これを文字化けと呼びます.
そこで, 世界共通で使用可能な文字コードを作ろうと策定されたものがUnicode (ユニコード) です.
Unicodeではコードポイントと呼ばれる一意な非負整数 (0, 1, 2, ...) が用意されており, その各数字と各文字とが1対1に対応しています.
日本語の例は下表です.
| コードポイント (10進数) | コードポイント (16進数) | 文字 |
|---|---|---|
| 12353 | 3042 | ぁ |
| 12354 | 3043 | あ |
| 12355 | 3044 | ぃ |
| 12356 | 3045 | い |
| 39378 | 99D2 | 駒 |
| 28580 | 6FA4 | 澤 |
このコードポイントに対して, 更に「コードポイントをどう符号化するか?」という文字符号化形式 (UTF: Unicode Transformation Format)も別途 策定されています.
現行では UTF-8, UTF-16, UTF-32 の3種類が定められていますが, 実際によく使うのは UTF-8 です.
UTF-8は,
8 bit = 1 byteずつの単位で符号化
1 byte目は何byte文字かの判定に使用
もし1byte目がASCIIの範囲内だったら, そのままASCIIとして使用し, ASCIIとの互換性を担保
もし1byte目がASCIIの範囲外だったら, その他の言語の文字
何bytes文字の指定範囲の分だけ続くbytesをまとめて1つの文字として扱う
2 ~ 6 bytesの可変長で対応
という特徴をもっています.
1 byte目の具体的な割り当ては下表です.
| 1 byte目の範囲 (2進数) | 1 byte目の範囲 (16進数) | 何byte文字? | 文字の種類 |
|---|---|---|---|
| 0 0000000 ~ 0 1111111 | 00 ~ 7F | 1 byte文字 | ASCII |
| 110 00010 ~ 110 11111 | C2 ~ DF | 2 bytes文字 | ラテン, ギリシャ, キリル, アラビア文字等 |
| 1110 0000 ~ 1110 1111 | E0 ~ EF | 3 bytes文字 | インド, 東アジアの文字 (漢字等) |
| 11110 000 ~ 11110 111 | F0 ~ F7 | 4 bytes文字 | 古代文字, 上記以外 |
また, 各byte文字の場合に, 実際にコードポイントとして使用する場所は下表です.
| 何byte文字? | コードポイントとして使う場所をxで表記 |
|---|---|
| 1 byte文字 | 0xxxxxxx |
| 2 bytes文字 | 110xxxxx 10xxxxxx |
| 3 bytes文字 | 1110xxxx 10xxxxxx 10xxxxxx |
| 2進数 | 10進数 | 16進数 | 2進数 | 10進数 | 16進数 | |
|---|---|---|---|---|---|---|
| 0000 | 0 | 0 | 1000 | 8 | 8 | |
| 0001 | 1 | 1 | 1001 | 9 | 9 | |
| 0010 | 2 | 2 | 1010 | 10 | A | |
| 0011 | 3 | 3 | 1011 | 11 | B | |
| 0100 | 4 | 4 | 1100 | 12 | C | |
| 0101 | 5 | 5 | 1101 | 13 | D | |
| 0110 | 6 | 6 | 1110 | 14 | E | |
| 0111 | 7 | 7 | 1111 | 15 | F |
例えば, UTF-8によって符号化されたbyte列 CF 80 E3 81 82 33 41 を読み取ってみましょう.
CFは2 bytes文字の範囲内なので, 「CF 80」という2 bytesで1文字
「CF 80」を2進数に基数変換すると「11001111 10000000」
青字部分を集めたコードポイントは「01111000000」
これは10進数で960
10進数で960というコードポイントはギリシャ文字の「π」という文字
E3は3 bytes文字の範囲内なので, 「E3 81 82」という3 bytesで1文字
「E3 81 82」を2進数に基数変換すると「11100011 10000001 10000010」
青字部分を集めたコードポイントは「0011000001000010」
これは10進数で12354
10進数で12354というコードポイントは日本語で「あ」という文字
33は1 byte文字の範囲内なので, 「33」という1 byteで1文字
「33」はASCIIで「3」という文字
41は1 byte文字の範囲内なので, 「41」という1 byteで1文字
「41」はASCIIで「A」という文字
となるので, 実際には πあ3A という文字列だったことがわかります.

文字化けさせてみよう
日本人がたまに直面する文字化けは, 日本固有のShift_JISと世界標準のUTF-8との間で起こるものです. VSCodeで実際に文字化けをさせてみましょう.
| UTF-8で表示 | Shift_JISで表示 | |
|---|---|---|
| UTF-8で保存 | 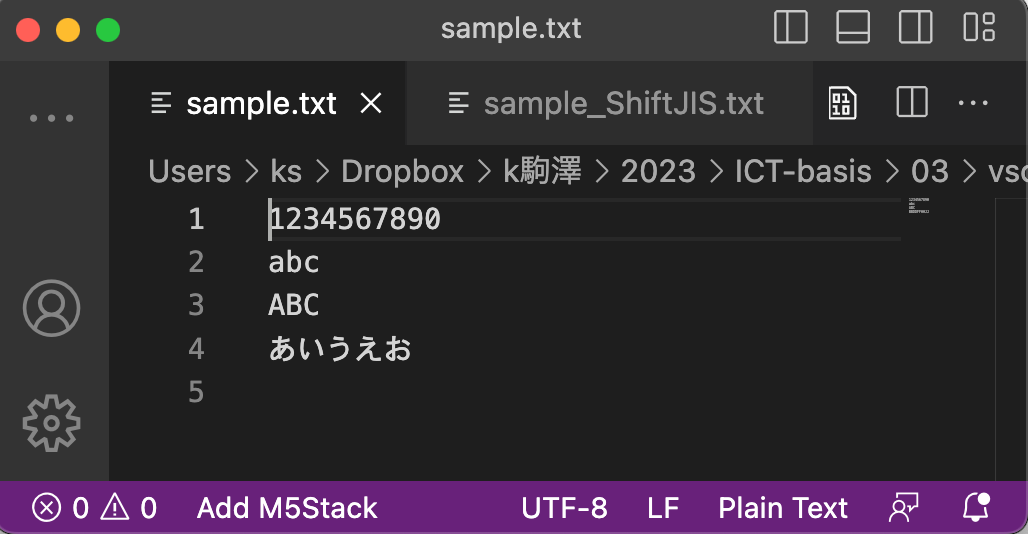 | 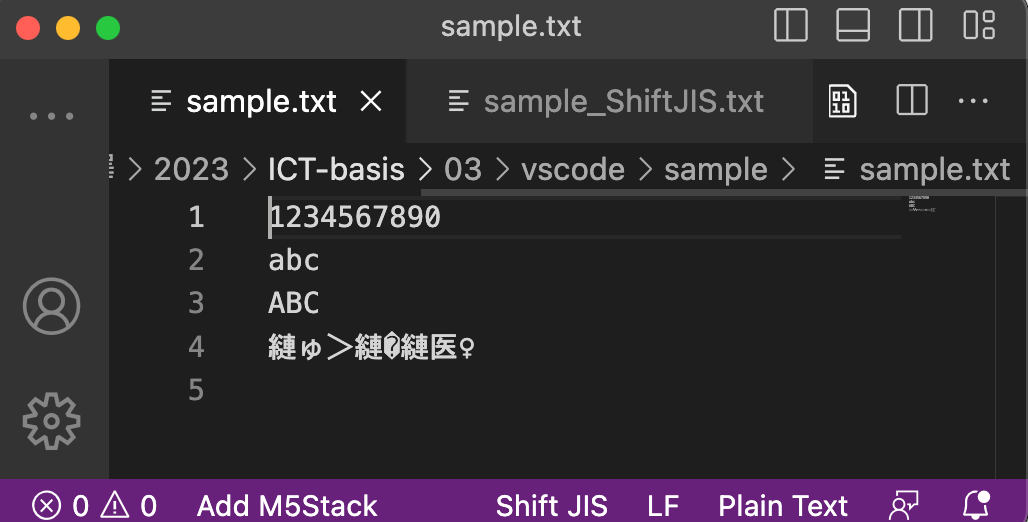 |
| Shift_JISで保存 | 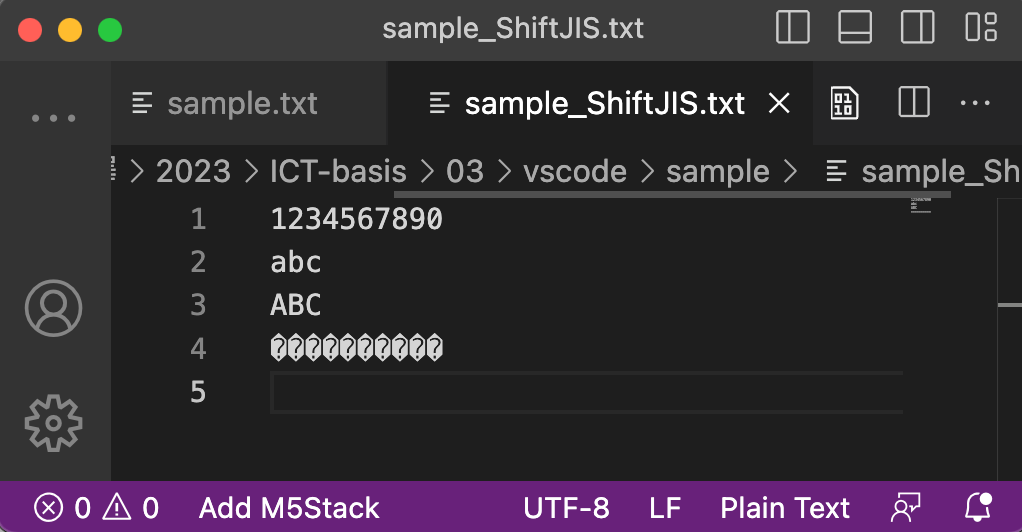 | 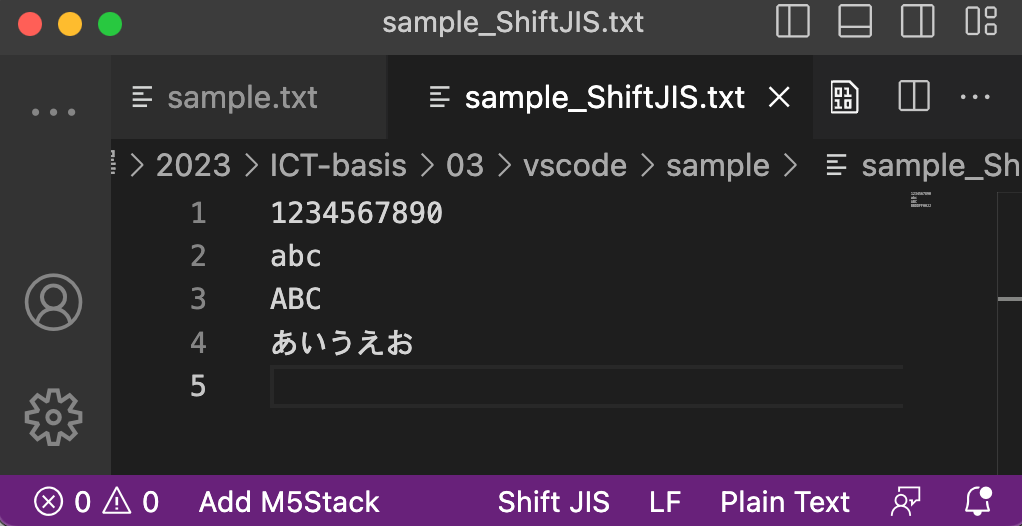 |
| 動画 |
画像ファイル
画像, 音, 動画を取り扱う拡張子は様々あり, 可逆性などについて特徴がありますので, 有名なものをいくつか紹介します.
ラスタとベクタ
画像の保存形式には, 実はラスタとベクタという2つの形式があります.
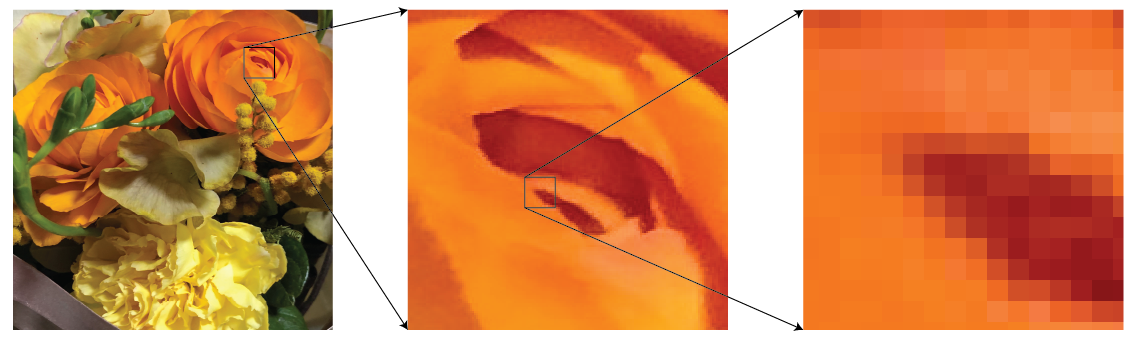
ラスタ形式 (raster) は, 前回のデジタル化でやったように, 画像をマス目 (ピクセル) に分け, その各ピクセルごとに色を決めていくという画像形式です.
これは, 写真などの複雑な画像の表現に向いています. しかし, ピクセル単位までしか細かく表現できないため, 画像を拡大していくと粗くなっていきます.
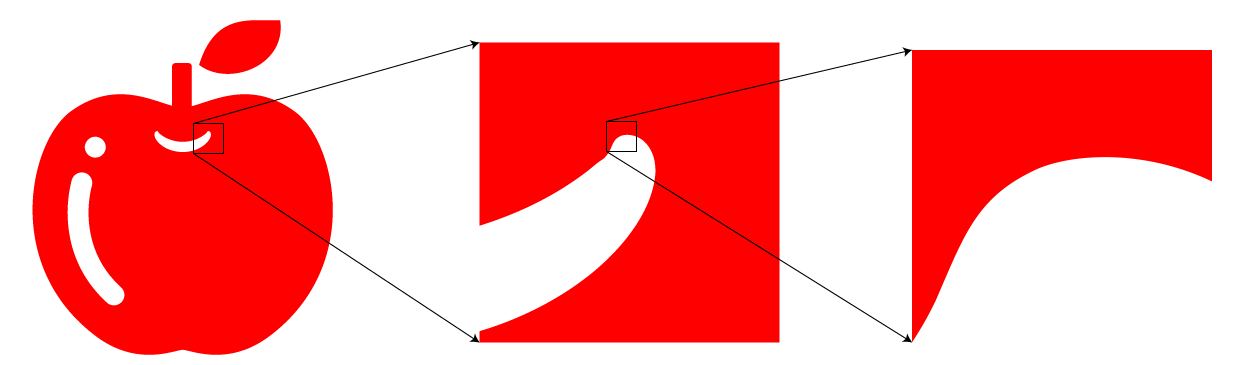
それに対し, ある空間内の点群の座標データとそれらをつなぐ線によって構成される画像形式をベクタ形式 (vector)と呼びます.
空間に対する数値データによる構成のため, 拡大しても粗くならないというメリットがあります. しかし, 複雑な画像を表現しようとすると, その分データ量が大きくなり, アプリ等で開くのに時間がかかるという問題もあります.
具体例 (ラスタ)
ラスタ形式の画像の代表例は下記です.
bmp (bitmap, ビットマップ)
(基本的には) 無圧縮
一応, 可逆圧縮の仕様も用意されている
→ ファイルサイズが大きくなりがち
白黒2値画像からフルカラーまで対応
非透過 (透明は表現できない)
gif (graphics interchange format, ジフ)
(基本的には) 可逆圧縮
一応, 非可逆圧縮の仕様も用意されている
256色以下
(基本的には) 非透過
透過表示できるように拡張されたものもある
アニメーション表示可能
一時期, gifで使用しているデータ圧縮アルゴリズムに特許使用料が発生していた. 2003年6月20日 (アメリカ), 2004年6月20日 (日本) に特許が失効し, 現在は自由に使用可能.
png (portable network graphics, ピング)
可逆圧縮
フルカラー (RGB 24bit) 以上の色表現も可
透過
gifに特許使用料が発生すると懸念されていた際に, gifに代わるものとして開発が開始された
pngファイルであることを表すために, バイナリの最初の部分 (ヘッダ) に「89 50 4E 47 0D 0A 1A 0A」という8 bytesが埋め込まれている
| 画像 | バイナリ |
 |
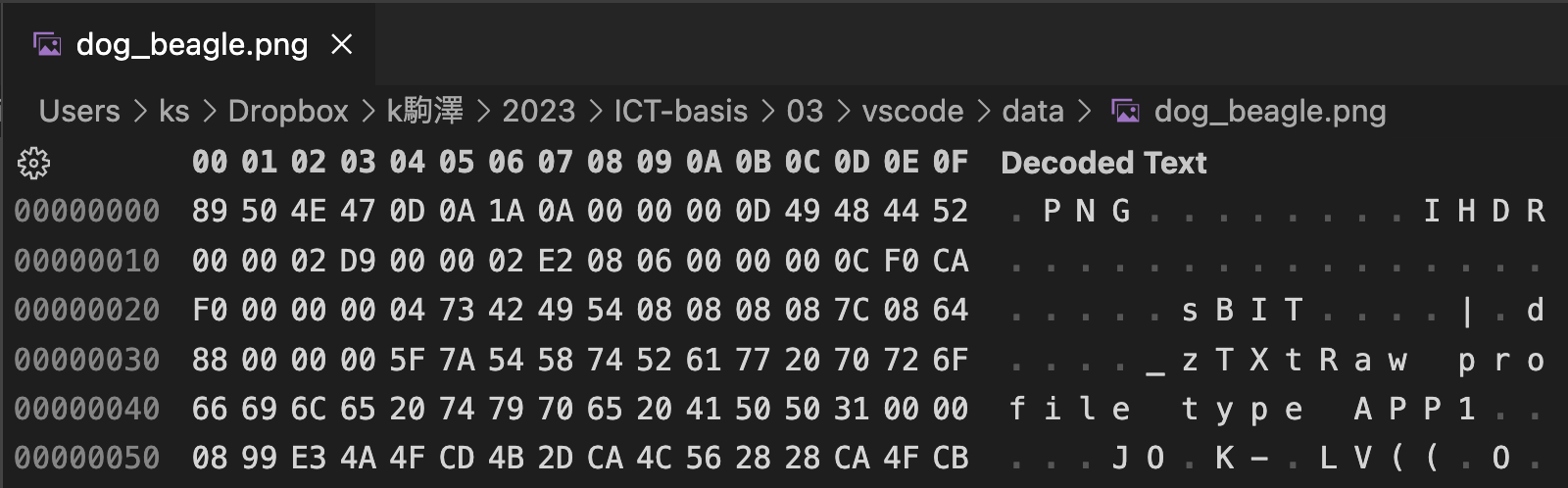 |
jpg, jpeg (joint photographic experts group)
(基本的には) 非可逆圧縮
一応, 可逆圧縮の仕様も用意されている
フルカラーまで対応
非透過
具体例 (ベクタ)
ベクタ形式の画像の代表例は下記です.
pdf (portable document format)
いわゆるpdfで, 主に電子文書のファイル形式として扱われるが, 内部でベクタ画像を扱うことが可能
svg (scalable vector graphics)
XML (extensible markup language) を基本とした画像形式
ウェブページを構成しているHTMLもマークアップ言語であるため, 親和性が高い
画像編集用のソフトでも勿論作成できるが, 中身はテキストで出来ているため, VS codeなどのテキストエディタで画像編集することも可能
よく見るブラウザ (Microsoft Edge, Chrome, Safari等)で実際の図を確認可能
x円<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 2 2"> <circle cx="1" cy="1" r="1" style="fill: rgb(3, 3, 3);"/></svg>
三角形<svg id="a" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 230.94 200"> <polygon points=".87 199.5 115.47 1 230.07 199.5 .87 199.5" style="fill: rgb(255, 0, 0);"/></svg>
| 種類 | 円 | 三角形 |
| テキストとして配置 | ||
| 画像として配置 |  |
 |
課題: circle.svgの色を赤 (red=255, green=0, blue=0) から青 (red=0, green=0, blue=255) に変えてみよう!!
文書構造
概要
誰かに何かを伝える文書やレポート, 論文等を作成する場合, 文書構造を意識して書くと良いです.
話題があちらこちらに飛んでいく文書よりも, 全体の流れと順番を整理して書かれた文書の方が読みやすいですよね.
最も一般的な文書構造は本です. 本のタイトルがあり, その中は第1章, 第2章と続いていきます. これは以前にフォルダとファイル構成の話で触れた木構造 (下記) となっています.
例0: 木構造の例: 大陸別の国名 (一部)
xxxxxxxxxxWorld├── Africa│ ├── Egypt│ └── Nigeria├── Antarctica├── Asia│ ├── China│ ├── Japan│ ├── Korea│ └── Thailand├── Europe│ ├── France│ ├── Germany│ └── UK├── North-America│ ├── Canada│ ├── Mexico│ └── USA├── Oceania│ ├── Australia│ └── New_Zealand└── South-America├── Brasil├── Chile└── Columbia
例1: 世界一周旅行 (内容は適当)
タイトル: 世界一周旅行
前書き
目次
第1章: 出発
第1節: 準備
第2節: 羽田空港
第2章: アジア
第1節: 韓国
第2節: 中国
第3節: タイ
第3章: ヨーロッパ
第1節: ギリシャ
第2節: オーストリア
第3節: イギリス
第1小節: イングランド
第2小節: ウェールズ
第3小節: スコットランド
第4小節: 北アイルランド
第4章: アメリカ
第1節: ニューヨーク
第2節: ロサンゼルス
第5章: 帰国
第1節: 羽田空港
後書き
例2: 銀河鉄道の夜 (宮沢賢治 著)
銀河鉄道の夜
本文
一、午后の授業
二、活版所
三、家
四、ケンタウル祭の夜
五、天気輪の柱
六、銀河ステーション
七、北十字とプリオシン海岸
八、鳥を捕る人
九、ジョバンニの切符
マークダウンファイル
上記のような構造化した文書を作成する際は, タイトル, 章, 節などの見出しと本文の違いが明確にわかるように表示した方が読みやすいです.
皆さんが普段閲覧しているウェブサイトはHTMLというマークアップ言語で構成されています. HTML自体は本科目の後半で実際にやるため, ここでは詳細は省きますが, マークアップ (mark up) の名の通り, 対象物に対して「印を付ける」ことで, 見出し, 箇条書き, 文字の色などを指定していきます.
HTMLの例:
xxxxxxxxxx見出し<h1>見出し1</h1><h2>見出し2</h2><h3>見出し3</h3>
箇条書き<ul><li>その1</li><li>その2</li></ul>
文字色<div style="color: red; ">このテキストは赤色になります.</div>しかし, 簡単にメモ等を取りたいと思った際に, 見出しなどの各要素を毎回<>と</>で囲むのは面倒です.
そこで, より簡単に構造的な文書を作成できる, マークダウン言語を紹介します.
マークダウンファイルの作成
VS codeを開きます
「ファイル」or「File」→「新規ファイル」or「New File」とクリックし, 新しいファイルを作成します
「ファイル」or「File」→「名前をつけて保存」or「Save As...」をクリック
Windows:
C:\Users\[ユーザ名]\Documents\ict\03or Mac:/Users/[ユーザ名]/Documents/ict/03というフォルダを指定し,markdown-test.mdというファイル名を入力し, フォーマットが「Markdown (*.md ... )」となっていることを確認し, 「保存」をクリックするWindows:
C:\Users\[ユーザ名]\Documents\ict\03\markdown-test.mdor Mac:/Users/[ユーザ名]/Documents/ict/03/markdown-test.mdというテキストファイルが作成できた
| Windows 10 |
マークダウン言語の基本
以下で紹介するマークダウン言語の記号はすべて半角英数で入力してください.
マークダウンの記号 (#や-) と実際のタイトル名 (World, 世界一周旅行など) の間に(半角スペース)を必ず入れてください.
見出し
見出しは# (半角のシャープ)の個数でタイトル, 章, 節を表記していきます
#, ## などと実際のタイトルとの間に(半角のスペース) を必ず入れてください
xxxxxxxxxx# World## Africa### Egypt### Nigeria
## Antarctica
## Asia### China### Japan### Korea### Thailand
箇条書き
箇条書きは- (半角のハイフン)で表します.
-の前にいくつか (2 or 4個の場合が多い) の半角スペースを入れると, 段が1つ深くなります.
xxxxxxxxxx買い物リスト- りんご- バナナ- 鍋物 - 白菜 - ネギ - 鍋の素
リンク
URLや他のファイルへのリンクは [リンク名](URL) で表します.
xxxxxxxxxx[Googleのページ](https://www.google.com/)
マークダウンのプレビューを表示する
VS Codeでマークダウンファイルを開いた状態にします
Windows: Ctrl キーとShiftキーを押したまま pキーを押します Mac: Command キーとShiftキーを押したまま pキーを押します
「markdown」と入力し, 「Markdown: Open Preview to the side」をクリックします

右側にプレビュー画面が表示されるようになりました
| Windows | Mac |
文書を構造化してみる
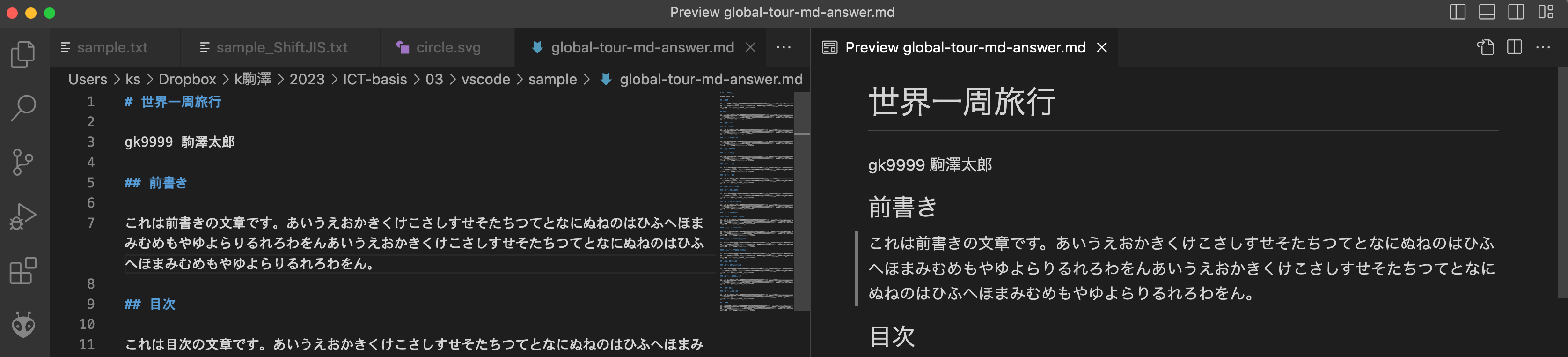
上記の例1の世界一周旅行の各見出しを実際にマークダウン言語で構造化してみましょう.
サンプルファイル (global-tour.md) をダウンロードし, 03フォルダに移動したら, VSCodeで開きましょう.
編集結果 (答え) のサンプル (md) 編集結果 (答え) のサンプル (pdf)
例1のタイトルや見出し等をマークダウンファイルで書いてみると下記のようになります. (文章部分は省略しています)
xxxxxxxxxx# タイトル: 世界一周旅行## 前書き## 目次行く予定の地域のリストは下記の通りです.- アジア- ヨーロッパ- アメリカ## 第1章: 出発### 第1節: 準備### 第2節: 羽田空港## 第2章: アジア### 第1節: 韓国### 第2節: 中国### 第3節: タイ## 第3章: ヨーロッパ### 第1節: ギリシャ### 第2節: オーストリア### 第3節: イギリス#### 第1小節: イングランド#### 第2小節: ウェールズ#### 第3小節: スコットランド#### 第4小節: 北アイルランド## 第4章: アメリカ### 第1節: ニューヨーク### 第2節: ロサンゼルス## 第5章: 帰国### 第1節: 羽田空港## 後書き## 参考文献[Google Map](https://www.google.co.jp/maps/)

| 動画 |
マークダウンファイルをpdf出力する
VSCodeの中でMarkdown pdfという拡張ツールをインストールすると, VSCodeを使ってマークダウンファイルをpdf化することができます.
Markdown pdfのインストール
VS Codeを開いた状態にする
左側の3つの四角と1つの四角が書かれたマーク
をクリックする左横に出てきた列の上部の検索ボックスに
markdown pdfと入力するMarkdown PDFというツールの
installボタンをクリックこれでMarkdown PDFという拡張ツールがVS Codeにインストールされた
| Windows | Mac |
Markdown pdfでpdf出力する
VSCodeでマークダウンファイルを開いた状態にする
右クリック or 2本指クリックをする
出てきた選択肢の中の「Markdown PDF: Export (pdf)」をクリックする
マークダウンファイルと同じ場所に, 同名のpdfファイルが作成された
| Windows | Mac |
PDF化の選択肢が出てこない場合 (Restricted Mode, 制限モード)
VS Codeでマークダウンファイルを開いた際に, Restricted Mode (制限モード) になっていると, 2本指クリック or 右クリックをしてもMarkdown PDFの選択肢が出てこない場合があります.
その場合は,
左下のRestricted Mode (制限モード) をクリックし,
Trust (信頼) をクリック
を実行すると, pdf化の選択肢が出るようになります.
| Windows | Mac |
広義のテキストファイル
テキストファイルという場合,
狭義には, txtという拡張子の文章ファイルを指しますが,
広義には, md (マークダウン), csv(表データ), svg (ベクタ画像), json (構造化データ) といった, 文字コードを利用したファイル全般を指すこともあります.
csvの例:
,(カンマ)で列を区切り, 改行で行を区切る
xxxxxxxxxx名前,学生番号佐藤太郎,st9999鈴木花子,sh1234
課題
提出締切: ● ICT基礎 木4: 2024-05-09 14:40 ● ICT基礎 木5: 2024-05-09 16:20
講義内で作成した下記の4つのファイルをzipにまとめ, 学生番号_ICT_03.zip (例: gk9999_ICT_03.zip) に変更し, 提出してください
UTF-8のテキストファイル (
utf8.txt)Shift_JISのテキストファイル (
shiftjis.txt)SVGファイル (
circle.svg)マークダウンファイル (
global-tour.md)


